Python爬虫 亚马逊网页的爬取
今天初步学习了python的爬虫,但是再练习过程中,对亚马逊商品网页的爬/取总是出现问题,可以看出亚马逊的反爬虫机制做的还是很好的。我通过不断尝试终于爬取到页面信息。
把经验分享给大家:
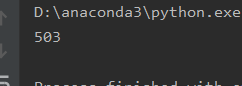
首先我用requests库的get方法爬取,发现状态码为503
|
1
2 3 4 5 6 |
import requests
url="https://www.amazon.cn/gp/product/B01M8L5Z3Y" r=requests.get(url) print(r.status_code) |
说明没有爬取到,然后我通过对头部信息的修改伪装成浏览器:
|
1
2 3 4 5 6 7 8 9 10 11 |
import requests
kv = {"user-agent": "Mozilla/5.0"} url="https://www.amazon.cn/gp/product/B01M8L5Z3Y" try: r=requests.get(url,headers=kv) r.raise_for_status() r.encoding=r.apparent_encoding print(r.text[:1000]) except: print("爬取失败") |
|
1
|
但是这次结果爬取到的并不是想要的结果,还是被服务器判断为自动程序:
|

然后根据提示,加入了cookie的相关部分:
最终代码如下:
|
1
2 3 4 5 6 7 8 9 10 11 12 13 |
import requests
from bs4 import BeautifulSoup kv = {"user-agent": "Mozilla/5.0"} cookie = { "cisession":"19dfd70a27ec0eecf1fe3fc2e48b7f91c7c83c60", "CNZZDATA100020196":"1815846425-1478580135-https%253A%252F%252Fwww.baidu.com%252F%7C1483922031", "Hm_lvt_f805f7762a9a237a0deac37015e9f6d9":"1482722012,1483926313", "Hm_lpvt_f805f7762a9a237a0deac37015e9f6d9":"1483926368" } url = 'https://www.amazon.cn/gp/product/B01M8L5Z3Y' r = requests.get(url,cookies=cookie,headers=kv) r.encoding = r.apparent_encoding print(r.text[:1000000]) |
最终爬到数据:

只是初学者,爬取的数据还有许多其他代码,数据比较繁多,在以后继续学习后,我会继续更新优质的爬虫,便于读取数据。