我是如何把python爬虫获取到的数据写入Excel的?
如何将爬虫获取的数据写入Excel,这一点我在爬虫文章几乎都是采用这种方式来进行操作的
写入Excel的目的是为了后续更加方便的使用pandas对数据进行清洗、筛选、过滤等操作。
为进一步数据研究、可视化打基础。
1. 自定义写入Excel
python写入Excel的方式有很多,常用的支持python操作的库有
xlsxwriter、pandas、openpyxl
今天咱们只介绍我常用到的openpyxl
1. 创建workbook
2.创建worsheet
3.数据写入sheet
4.数据写入sheet
5.保存到excel
既然说到爬虫数据写入Excel。那我们直接上爬虫案例
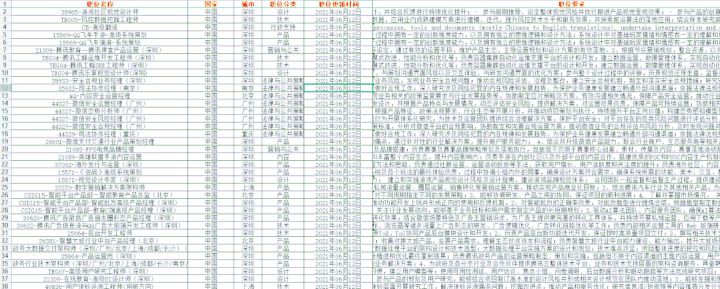
 如图我们现在已经成功的将数据打印出来了,接下来我们考虑的就是如何将这些数据保存到Excel中。
如图我们现在已经成功的将数据打印出来了,接下来我们考虑的就是如何将这些数据保存到Excel中。
 前面说到我们这里使用的Python库是openpyxl来实现这一操作。
所以第一步
openpyxl的下载
前面说到我们这里使用的Python库是openpyxl来实现这一操作。
所以第一步
openpyxl的下载
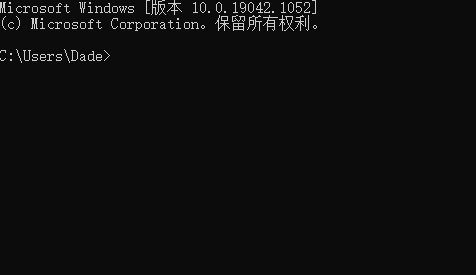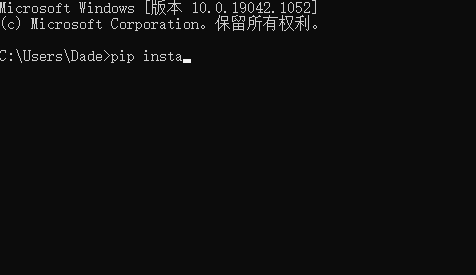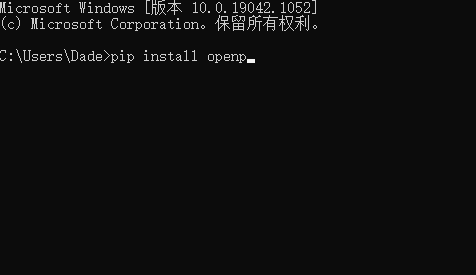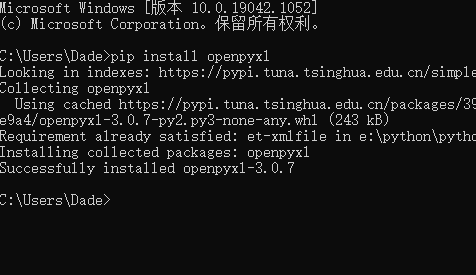 或者自行下载whl文件安装
或者自行下载whl文件安装
 导入库
使用import导入openpyxl库,为后续方便调用,
可以使用as关键字来简写库名
1. 创建workbook
2.创建worsheet
3. 头文件
3.数据写入sheet
4.保存excel
四步走轻松将你的数据写入到Excel
导入库
使用import导入openpyxl库,为后续方便调用,
可以使用as关键字来简写库名
1. 创建workbook
2.创建worsheet
3. 头文件
3.数据写入sheet
4.保存excel
四步走轻松将你的数据写入到Excel
 还有更多的表头、边框、颜色设置等在此不再赘述哈
有需要的可自行百度哈。
2. 函数式写入Excel
还有更多的表头、边框、颜色设置等在此不再赘述哈
有需要的可自行百度哈。
2. 函数式写入Excel
 3. pandas写入Excel
3. pandas写入Excel
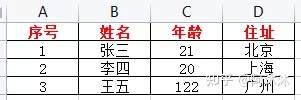
如图我们现在已经成功的将数据打印出来了,接下来我们考虑的就是如何将这些数据保存到Excel中。
https://www.lfd.uci.edu/~gohlke/pythonlibs/
import openpyxl as op
ws = op.Workbook()
wb = ws.create_sheet(index=0)
wb.cell(row=1, column=1, value='职位名称')
wb.cell(row=1, column=2, value='国家')
wb.cell(row=1, column=3, value='城市')
wb.cell(row=1, column=4, value='职位分类')
wb.cell(row=1, column=5, value='职位更新时间')
wb.cell(row=1, column=6, value='职位要求')
# 加入count是为了换行写入数据
count = 2
# 要写入excel的数据
post_name = job['RecruitPostName'] # 职位名称
country_name = job['CountryName'] # 国家
loc_name = job['LocationName'] # 城市
category_name = job['CategoryName'] # 职位分类
last_up_time = job['LastUpdateTime'] # 职位更新时间
responsibility = job['Responsibility'] # 职位要求
# 打印获取到的数据
print(post_name, country_name, loc_name, category_name, last_up_time, responsibility)
# 将数据写入到下一行
wb.cell(row=count, column=1, value=post_name)
wb.cell(row=count, column=2, value=country_name)
wb.cell(row=count, column=3, value=loc_name)
wb.cell(row=count, column=4, value=category_name)
wb.cell(row=count, column=5, value=last_up_time)
wb.cell(row=count, column=6, value=responsibility)
# count加1,进入到下一行写入数据
count += 1
# 保存数据
ws.save('腾讯职位.xlsx')
import openpyxl as op
id = [1, 2, 3]
name = ['张三', '李四', '王五']
age = [21, 20, 122]
address = ['北京', '上海', '广州']
infos = [id, name, age, address]
def op_toexcel(data): # openpyxl库储存数据到excel
wb = op.Workbook() # 创建工作簿对象
ws = wb['Sheet'] # 创建子表
ws.append(['序号', '姓名', '年龄', '住址']) # 添加表头
for i in range(len(data[0])):
d = data[0][i], data[1][i], data[2][i], data[3][i]
ws.append(d) # 每次写入一行
wb.save('测试.xlsx')
id = [1, 2, 3]
name = ['张三', '李四', '王五']
age = [21, 20, 122]
address = ['北京', '上海', '广州']
infos = [id, name, age, address]
# pandas库储存数据到excel
def pd_toexcel(data):
# 用字典设置DataFrame所需数据
dfData = {
'序号': data[0],
'姓名': data[1],
'年龄': data[2],
'住址': data[3]
}
# 创建DataFrame
df = pd.DataFrame(dfData)
# 存表,去除原始索引列(0,1,2...)
df.to_excel('测试.xlsx', index=False)
